Foundation Models Explained: From AI's Origins to Talking to an LLM (Free Video Series)
Back in 2025, I built a video curriculum I called the Agentic AI Software Engineer series. The goal was straightforward: take software engineers who were curious about AI and give them a real grounding in how these systems actually work, not just how to call an API, but what’s happening underneath.
I sat on this particular module for a while. Today I’m releasing it publicly, because these fundamentals have only gotten more relevant as the space has accelerated. The marketing noise around AI is louder than ever, and the engineers I see struggle most are the ones who skipped the foundations and jumped straight to building. This series is the antidote to that.
Four videos. Around 60 minutes total.
Contents
- A Beginner’s Guide to the Origins of AI (1950s–2020s)
- How Foundation Models Like Claude and GPT Are Trained
- Post-Training: From Token Predictor to Conversational AI
- Interacting with an LLM Using a Vendor Console
A Beginner’s Guide to the Origins of AI (1950s–2020s)
Before we can talk about GPT or Claude, we need to understand how we got here. AI didn’t appear from nowhere in 2022, it’s the result of decades of ideas, dead ends, breakthrough moments, and reinventions.
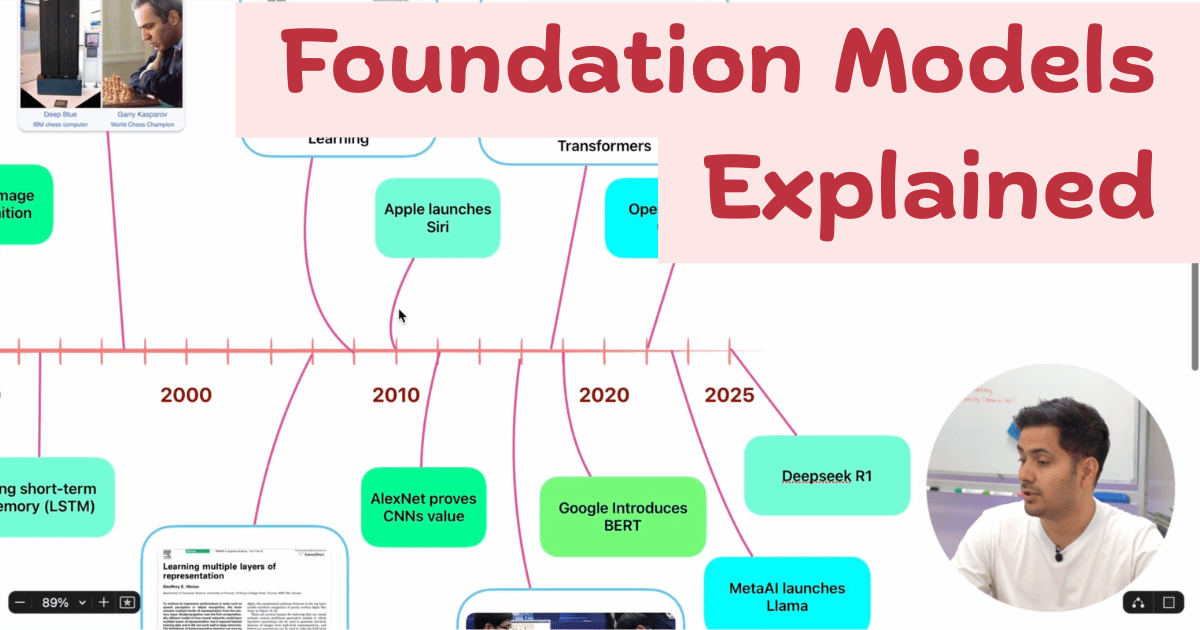
This video walks through a timeline of the key milestones:
- 1950s The birth of the field. Turing’s foundational question (Can machines think?), the Dartmouth Conference that named “artificial intelligence”, and the first perceptrons.
- The AI Winters What happens when a field overpromises. Funding dried up, twice. Understanding why matters if you want to reason clearly about today’s hype cycles.
- 1980s & 90s The resurgence of expert systems and the symbolic AI approach, followed by IBM’s Deep Blue defeating Kasparov in 1997, a landmark that forced the world to reckon with what machines could do.
- 2000s & 2010s The deep learning revolution. GPUs, big data, and the return of neural networks. The ImageNet moment in 2012 changed everything for the field.
- 2017 The transformer architecture arrives in the Attention Is All You Need paper. Everything that followed traces back to this.
- 2022 ChatGPT launches and AI goes mainstream overnight.
- Today Multimodal foundation models are the leading wave.
If you only have 15 minutes and you want the context that makes everything else in AI click, start here.
How Foundation Models Like Claude and GPT Are Trained
The second video goes inside the training process of a foundation model. This is the part that most tutorials skip, and it’s the part that explains why these models behave the way they do.
We cover:
- Data collection The scale and composition of training data, and why data quality shapes model behaviour more than almost any other factor.
- Tokenization How raw text is broken into tokens, why this matters for how models process language, and why “tokens ≠ words” is something every practitioner needs to internalize.
- Transformer architecture The self-attention mechanism explained at the right level of detail: enough to build intuition, not so much that it becomes a linear algebra lecture.
- Pre-training What the model is actually doing during pre-training (next-token prediction at massive scale), and why a model trained this way is powerful but not yet useful on its own.
By the end of this video you’ll have a clear mental model of why training requires so much compute, what the model has actually learned, and why pre-training alone produces something impressive but incomplete.
Post-Training: From Token Predictor to Conversational AI
A pre-trained model is a next-token predictor. It can generate coherent text, but it has no concept of following instructions, being helpful, or avoiding harmful outputs. Turning that raw capability into something you can actually use — that’s what post-training is about.
This is one of the most interesting videos in the series. We go through:
- Fine-tuning Adapting the base model on curated data to shape its behaviour toward specific tasks.
- Instruction tuning Teaching the model to follow instructions rather than just complete text. This is what makes a model feel like an assistant.
- RLHF (Reinforcement Learning from Human Feedback) — The key technique behind aligning model outputs with human preferences. How it works, why it works, and what it can’t fix.
- Hallucinations Where they come from and what post-training techniques do (and don’t do) to address them.
- Tool use How models are taught to call external tools and retrieve real-world data, which is the foundation of every agentic application being built today.
If you’re building anything with AI, understanding this pipeline changes how you think about prompt engineering, model selection, and what you can realistically expect from a model.
Interacting with an LLM Using a Vendor Console
The final video bridges theory and practice. We’ve covered history, training, and alignment — now we actually sit down and talk to a model.
This lesson covers the core concepts you need to use any LLM effectively:
- System prompts What they are, how they shape model behaviour, and why getting this right is the most underrated skill in applied AI.
- Token usage Reading and reasoning about token counts, context windows, and what happens at the edges.
- Temperature and sampling What temperature actually controls, and how to tune it for different use cases (creative vs. deterministic tasks).
- Few-shot prompting How to give the model examples to pattern-match against, and when this technique dramatically outperforms zero-shot prompting.
- Vendor console walkthrough We explore Mistral AI’s console and other provider interfaces, so you know what to look for regardless of which provider you’re using.
Why I’m Releasing This Now
I built this curriculum for engineers inside a structured program, but the fundamentals don’t expire. If anything, the pace of change in AI makes it more important to have a solid grounding, because without it, every new model release or research paper is noise rather than signal.
If you’re an engineer getting serious about building with AI, this is a good 60 minutes to spend. Watch it sequentially, each video builds on the last.